解密資料路徑上的 Activator ¶
發布於:2024-03-20 , 修訂於:2024-03-22
解密資料路徑上的 Activator¶
作者:Stavros Kontopoulos,RedHat 首席軟體工程師
在本部落格文章中,您將了解如何識別 Activator 何時在資料路徑上,以及觸發該行為的原因。
Knative 服務在提供流量時可以兩種模式運作:proxy 模式和 serve 模式。當處於 proxy 模式時,activator 元件會在資料路徑上(這表示傳入的請求會透過 activator 路由),並且它會保持在路徑上直到滿足某些條件(稍後會詳細介紹)。如果滿足這些條件,則會從資料路徑中移除 activator,且服務會轉換為 serve 模式。例如,當服務從/縮放至零時,預設會將 activator 新增至資料路徑。此預設設定常常讓使用者感到困惑,因為除非有足夠的容量可用,否則不會從路徑中移除 activator。這是故意的,因為 activator 的角色之一是提供反壓功能(充當請求緩衝區),以便 Knative 服務不會因傳入的流量而過載。此外,Knative 服務可以使用註解來定義它可以處理多少流量。自動調整程式元件將使用此資訊來計算處理特定 Knative 服務傳入流量所需的 Pod 數量。
背景¶
Knative 中的預設 Pod 自動調整程式 (KPA) 是一種複雜的演算法,它使用來自 Pod 的指標來做出縮放決策。讓我們詳細了解建立新的 Knative 服務時會發生什麼事。
一旦使用者建立新的服務,對應的 Knative 調節器會為該服務建立 Knative Configuration 和 Knative Route(有關 Knative K8s 資源的詳細資訊,請參閱此處)。然後,Configuration 調節器會建立 Revision 資源,而後者的調節器會為該服務建立 PodAutoscaler (PA) 資源以及 K8s 部署。Route 調節器會建立 Ingress 資源,該資源將被負責在本機叢集和叢集外部管理流量的 Knative net-* 元件接收。
現在,PA 的建立會觸發 KPA 調節器,它會執行某些步驟來為修訂設定自動縮放組態
-
建立一個內部 Decider 資源,該資源會將初始所需縮放比例保留在
decider.Status.DesiredScale中,並透過 multi-scaler 元件設定 Pod 縮放器。Pod 縮放器每兩秒鐘計算一次新的 Scale 結果,並根據所需縮放比例是否不等於 Pod 數量的情況做出決策。如果不是,則會觸發 KPA 調節器的新調節。目標是讓 KPA 取得最新的縮放結果。 -
建立一個 Metric 資源,該資源會觸發指標收集器控制器為修訂 Pod 設定 scraper。
-
呼叫一個縮放方法,該方法會決定所需的 Pod 數量,並更新對應於修訂的 K8s 原始部署。
-
建立/更新一個
ServerlessService(SKS),該服務會保留有關操作模式(proxy 或 serve)的資訊,並儲存 proxy 模式中應使用的 activator 數量。SKS 中指定的 activator 數量取決於需要涵蓋的容量。 -
更新 PA 並在 PA 的狀態中報告作用中和所需的 Pod
注意
上面的 SKS 建立/更新事件會觸發其特定控制器的 SKS 調節,該控制器會建立所需的公用和私有 K8s 服務,以便將流量路由到原始 K8s 部署。此外,在 proxy 模式中,SKS 控制器會接收 activator 的數量,並為修訂的公用服務設定相等數量的端點。結合 Knative 網路元件(由 Ingress 資源驅動)完成的網路設定,這大致是 Knative 服務 (ksvc) 準備好提供流量所需發生的端對端網路設定。Knative 網路元件可以是下列任何一種:net-istio、net-kourier、net-contour 和 net-gateway-api。
實務中的容量和操作模式¶
如先前所述,如果有足夠的容量可用,則會從路徑中移除 activator。讓我們看看如何計算此容量,但在那之前,讓我們先介紹兩個概念:panic 和 stable 視窗。panic 視窗是指表示缺乏服務流量容量的時間長度。它通常發生在流量突然爆發時。描述何時進入 panic 模式並開始 panic 視窗的條件為
dppc/readyPodsCount >= spec.PanicThreshold
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
dppc 代表所需的 panic Pod 數量,並表示自動調整程式需要在 panic 模式中實現的目標。目標值是自動調整程式旨在達到的並發使用率,計算方式為 0.7*(revision_total)。修訂總數是 Pod 上允許的縮放指標的最大可能值,預設為 100(容器並發預設值)。值 0.7 是每個複本的使用率因素,當達到該值時,我們需要向外縮放。
注意
如果使用 KPA 指標每秒請求數 (RPS),則使用率因素為 0.75。
observedPanicValue 是在 panic 視窗期間針對並發指標看到的計算平均值。panic 臨界值是可設定的(預設為 2),並表示所需 Pod 與可用 Pod 的比例。
在我們進入 panic 模式後,為了退出,我們需要有足夠的容量來維持一段等於 stable 視窗大小的時間。這也表示自動調整程式會嘗試準備好足夠的 Pod,以便增加容量。此外,請注意,當在 panic 模式之外運作時,自動調整程式不會使用 dpcc,而是使用類似的數量:dspc := math.Ceil(observedStableValue / spec.TargetValue),這是基於 stable 期間的指標。
為了量化足夠容量的概念並處理流量爆發,我們引入了需要為非負數的過剩爆發容量 (EBC) 的概念。其定義為
EBC = TotalCapacity - ObservedPanicValue - TargetBurstCapacity.
TotalCapacity 的計算方式為 ready_pod_count*revision_total。預設的 TargetBurstCapacity (TBC) 設定為 200。
在這一點上,我們可以正式定義從路徑中移除 activator 所依據的條件
重要
如果 EBC >= 0,則我們有足夠的容量來處理流量,並且啟動器 (activator) 將從路徑中移除。
現在,使用上述預設值,並考量到請求需要停留一段時間,以便並行指標顯示足夠的計數期間負載,這意味著你無法在請求很快完成的 hello-world 範例中得到 EBC >= 0 的結果。 後者通常會讓新手感到困惑,因為他們會覺得 Knative 服務從未進入服務模式。 在下一個範例中,我們將展示 Knative 服務的生命週期,它也會進入服務模式,以及 EBC 在實務上是如何計算的。 此外,此範例使用一個範例應用程式,該應用程式透過睡眠操作來控制請求停留的時間,請參閱 自動縮放範例應用程式 - Go 章節。 因此,以下是範例的服務,其目標並行值為 10,且 tbc=10
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: autoscale-go
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/target-burst-capacity: "10"
spec:
containers:
- image: ghcr.io/knative/autoscale-go:latest
我們將要示範的情境是部署 ksvc,使其縮減至零,然後發送流量 10 分鐘。 然後,我們從自動調整器 (autoscaler) 收集日誌,並視覺化 EBC 值、就緒的 Pod 和隨時間的恐慌模式。 圖表如下所示。
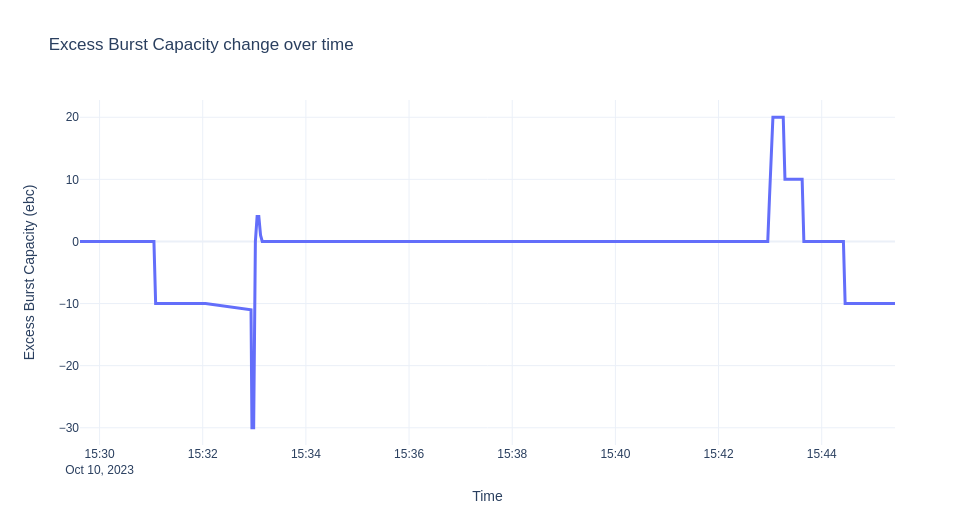
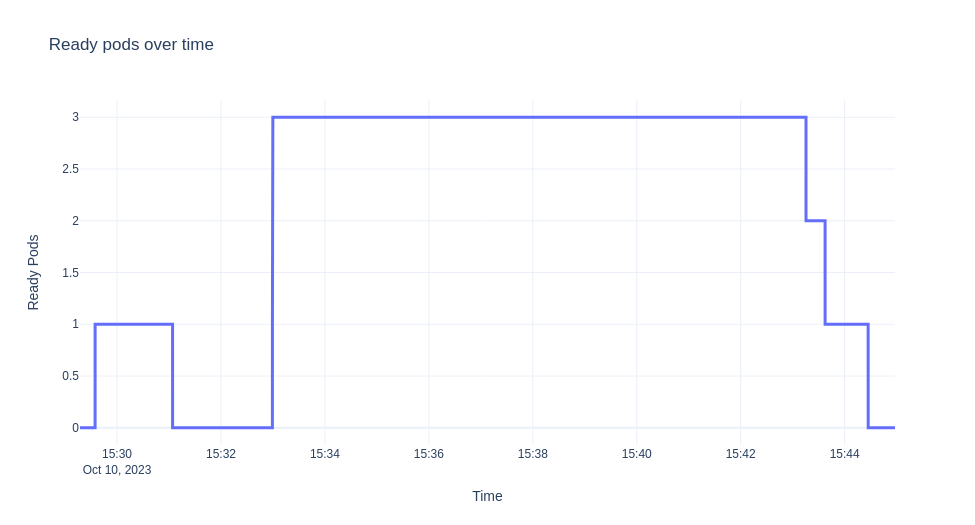
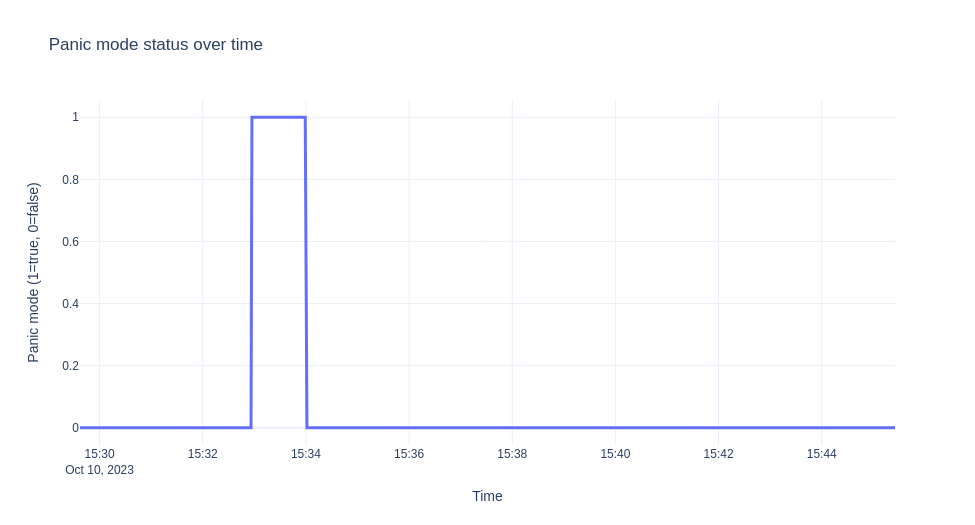
注意
此實驗在 Minikube 上執行,並使用 hey 工具產生流量。
讓我們詳細描述一下我們在上面看到的內容。 最初,當部署 ksvc 時,沒有流量,並且預設會建立一個 Pod 以進行驗證。
在 Pod 啟動之前,我們有:
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Proxy 2 autoscale-go-00001 autoscale-go-00001-private Unknown NoHealthyBackends
$ kubectl get po
NAME READY STATUS RESTARTS AGE
autoscale-go-00001-deployment-6cc679b9d6-xgrkf 2/2 Running 0 24s
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Serve 2 autoscale-go-00001 autoscale-go-00001-private True
我們處於服務模式的原因是因為 EBC=0。當你啟用偵錯日誌時,在日誌中你會得到:
...
"timestamp": "2023-10-10T15:29:37.241575214Z",
"logger": "autoscaler",
"message": "PodCount=1 Total1PodCapacity=10.000 ObsStableValue=0.000 ObsPanicValue=0.000 TargetBC=10.000 ExcessBC=0.000",
EBC = 10 - 0 - 10 = 0
請注意,由於沒有流量,我們在恐慌或穩定期間看不到任何觀察結果。
由於沒有流量,我們縮減回零,並且 sks 回到代理模式
$ kubectl get sks
NAME MODE ACTIVATORS SERVICENAME PRIVATESERVICENAME READY REASON
autoscale-go-00001 Proxy 2 autoscale-go-00001 autoscale-go-00001-private Unknown NoHealthyBackends
讓我們發送一些流量。
hey -z 600s -c 20 -q 1 -host "autoscale-go.default.example.com" "http://192.168.39.43:32718?sleep=1000"
最初,當啟動器收到請求時,它會將統計資訊傳送至自動調整器,後者會嘗試根據一些初始縮放(預設值為 1)從零開始縮放。
...
"timestamp": "2023-10-10T15:32:56.178498172Z",
"logger": "autoscaler.stats-websocket-server",
"caller": "statserver/server.go:193",
"message": "Received stat message: {Key:default/autoscale-go-00001 Stat:{PodName:activator-59dff6d45c-9rdxh AverageConcurrentRequests:1 AverageProxiedConcurrentRequests:0 RequestCount:1 ProxiedRequestCount:0 ProcessUptime:0 Timestamp:0}}",
"address": ":8080"
由於我們的容量不足,自動調整器會進入恐慌模式,EBC 為 10*0 -1 -10 = -11
...
"timestamp": "2023-10-10T15:32:56.178920551Z",
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:286",
"message": "PodCount=0 Total1PodCapacity=10.000 ObsStableValue=1.000 ObsPanicValue=1.000 TargetBC=10.000 ExcessBC=-11.000",
"timestamp": "2023-10-10T15:32:57.24099875Z",
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:215",
"message": "PANICKING."
...
"timestamp":"2023-10-10T15:32:56.949001622Z",
"logger":"autoscaler.stats-websocket-server",
"message":"Received stat message: {Key:default/autoscale-go-00001 Stat:{PodName:activator-59dff6d45c-9rdxh AverageConcurrentRequests:18.873756322609804 AverageProxiedConcurrentRequests:0 RequestCount:19 ProxiedRequestCount:0 ProcessUptime:0 Timestamp:0}}",
"address":":8080"
...
"timestamp":"2023-10-10T15:32:56.432854252Z",
"logger":"autoscaler",
"caller":"kpa/kpa.go:188",
"message":"Observed pod counts=kpa.podCounts{want:1, ready:0, notReady:1, pending:1, terminating:0}",
...
"timestamp":"2023-10-10T15:32:57.241052566Z",
"logger":"autoscaler",
"message":"PodCount=0 Total1PodCapacity=10.000 ObsStableValue=19.874 ObsPanicValue=19.874 TargetBC=10.000 ExcessBC=-30.000",
根據新的統計資訊,kpa 決定在某個時間點將規模擴展至 3 個 Pod。
"timestamp": "2023-10-10T15:32:57.241421042Z",
"logger": "autoscaler",
"message": "Scaling from 1 to 3",
但讓我們看看為什麼會這樣。 上述日誌來自多重縮放器,該縮放器會報告一個縮放結果,其中包含如上所述報告的 EBC 和不同期間的所需 Pod 數量。
最終所需的數字大致是從我們之前看到的 dppc 得出的(還有更多邏輯涵蓋邊緣情況並檢查最小/最大縮放限制)。
在此情況下,目標值為 0.7*10=10。 因此,舉例來說,對於恐慌期間:dppc=ceil(19.874/7)=3。
隨著指標趨於穩定且修訂版已充分縮放,我們有:
"timestamp": "2023-10-10T15:33:01.320912032Z",
"logger": "autoscaler",
"caller": "kpa/kpa.go:158",
"message": "SKS should be in Serve mode: want = 3, ebc = 0, #act's = 2 PA Inactive? = false",
...
"logger": "autoscaler",
"caller": "scaling/autoscaler.go:286",
"message": "PodCount=3 Total1PodCapacity=10.000 ObsStableValue=16.976 ObsPanicValue=15.792 TargetBC=10.000 ExcessBC=4.000",
EBC = 3*10 - floor(15.792) - 10 = 4
然後,當我們達到所需的 Pod 數量且指標穩定時,我們得到:
"timestamp": "2023-10-10T15:33:59.24118625Z",
"logger": "autoscaler",
"message": "PodCount=3 Total1PodCapacity=10.000 ObsStableValue=19.602 ObsPanicValue=19.968 TargetBC=10.000 ExcessBC=0.000",
幾秒鐘後,在我們進入恐慌模式一分鐘後,我們進入穩定模式(解除恐慌)。
"timestamp": "2023-10-10T15:34:01.240916706Z",
"logger": "autoscaler",
"message": "Un-panicking.",
"knative.dev/key": "default/autoscale-go-00001"
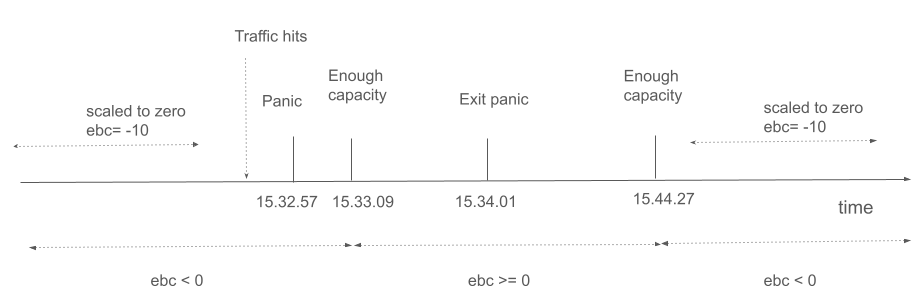
當我們有足夠的容量直到流量停止並且部署縮減回零(啟動器從路徑中移除)時,sks 也會轉換為 serve 模式。 對於上述實驗,由於我們有穩定的流量近 10 分鐘,因此只要我們有足夠的 Pod 準備就緒,我們就不會觀察到任何變化。 請注意,當流量下降且在我們調整 Pod 數量之前,在一段短時間內,我們擁有的 ebc 會超出我們的需求。
主要事件也顯示在下方的時間軸中
結論¶
服務如何以及為何停留在代理模式,或者當啟動器位於資料路徑上時,使用者如何管理啟動器,這些問題通常令人困惑。 這很重要,特別是當你剛開始使用 Knative Serving 時。 透過上述詳細範例,希望我們已經揭開了 Serving 資料平面的這種基本行為的神秘面紗。